
豆包大模型开源了吗(豆包包本包)
DouJia 2025-03-08 02:30 273 浏览
机器之心原创
记者:老红
编辑:吴攀
")
9 月中旬豆包大模型开源了吗,微软报告豆包大模型开源了吗了在语音识别方面取得的新里程碑:新系统的识别词错率降至 6.3%;一个月后,微软又公布了在这一领域成功实现了历史性突破:他们的语音识别系统实现了和专业转录员相当甚至更低的词错率(WER),达到了 5.9%豆包大模型开源了吗!机器之心在此期间曾对微软首席语音科学家黄学东进行了专访,探讨了这一连串突破性背后的技术和语音识别领域未来的可能性。近日,机器之心又对微软研究院首席研究员俞栋进行了一次独家专访,谈论了深度学习与语音识别相辅相成的发展以及相关领域的现状和未来。
俞栋简介:1998 年加入微软公司,现任微软研究院首席研究员,兼任浙江大学兼职教授和中科大客座教授。语音识别和深度学习方向的资深专家,出版了两本专著,发表了 160 多篇论文,是 60 余项专利的发明人及深度学习开源软件 CNTK 的发起人和主要作者之一。曾获 2013 年 IEEE 信号处理协会最佳论文奖。现担任 IEEE 语音语言处理专业委员会委员,曾担任 IEEE/ACM 音频、语音及语言处理汇刊、IEEE 信号处理杂志等期刊的编委。
以下是此次专访的内容:
机器之心:请俞老师先给我们的读者介绍一下目前语音识别方面最值得关注的一些方向。
俞栋:在安静环境下并使用近距麦克风的场合,语音识别的识别率已越过了实用的门槛;但是在某些场景下效果还不是那么好,这就是我们这个领域的 frontier。现在大家主攻几点:
首先,是不是能够进一步提升在远场识别尤其是有人声干扰情况下的识别率。目前一般远场识别的错误率是近场识别错误率的两倍左右,所以在很多情况下语音识别系统还不尽如人意。远场识别至少目前还不能单靠后端的模型加强来解决。现在大家的研究集中在结合多通道信号处理(例如麦克风阵列)和后端处理从拾音源头到识别系统全程优化来增强整个系统的 表现。
另外,大家还在研究更好的识别算法。这个「更好」有几个方面:一个方面是能不能更简单。现在的模型训练过程还是比较复杂的,需要经过很多步骤。如果没有 HTK 和 Kaldi 这样的开源软件和 recipe 的话,很多团队都要用很长时间才能搭建一个还 OK 的系统即使 DNN 的使用已经大幅降低了门槛。现在因为有了开源软件和 recipe,包括像 CNTK 这样的深度学习工具包,事情已经容易多了,但还有继续简化的空间。这方面有很多的工作正在做,包括如何才能不需要 alignment 、或者不需要 dictionary。现在的研究主要还是基于 end-to-end 的方法,就是把中间的一些以前需要人工做的步骤或者需要预处理的部分去掉。虽然目前效果还不能超越传统的 hybrid system,但是已经接近 hybrid system 的 performance 了。
另外一个方面,最近的几年里大家已经从一开始使用简单的 DNN 发展到了后来相对复杂的 LSTM 和 Deep CNN 这样的模型。但在很多情况下这些模型表现得还不够好。所以一个研究方向是寻找一些特殊的网络结构能够把我们想要 model 的那些东西都放在里面。我们之前做过一些尝试,比如说人在跟另外一个人对话的过程中,他会一直做 prediction,这个 prediction 包括很多东西,不单是包括你下一句想要说什么话,还包括根据你的口音来判断你下面说的话会是怎样等等。我们曾尝试把这些现象建在模型里以期提升识别性能。很多的研究人员也在往这个方向走。
还有一个方向是快速自适应的方法—就是快速的不需要人工干预的自适应方法(unsupervised adaptation)。现在虽然已经有一些自适应的算法了,但是它们相对来说自适应的速度比较慢,或者需要较多的数据。有没有办法做到更快的自适应豆包大模型开源了吗?就好像第一次跟一个口音很重的人说话的时候,你可能开始听不懂,但两三句话后你就可以听懂了。大家也在寻找像这种非常快还能够保证良好性能的自适应方法。快速自适应从实用的角度来讲还是蛮重要的。因为自适应确实在很多情况下能够提升识别率。
从识别来讲,我觉得目前主要是这些方向。
机器之心:Google DeepMind 最近提出了一种通过学习合成波形的方式生成语音的技术 WaveNet,据说可以生成感觉更自然的语音,微软在这方面有什么研究项目?
俞栋:微软也在做类似的工作,但是因为合成的研究团队和工程团队都在中国,我对他们具体到哪个地步不是特别清楚。有一些信息我也不能直接披露,所以就不详细讲了。
机器之心:深度学习已经在语音识别得到了非常出色的表现,您觉得未来语音识别还能在深度学习的哪些方面实现突破?
俞栋:刚才我讲了,其中的一个可能性就是通过各种类型的 prediction 和 adaptation 使得深度学习模型表现更出色,这是有可能继续提升的地方。另外就是 end-to-end 建模。
还有,像我们最近也在做一些特殊环境中的语音识别,比如说在高噪音环境下、或者你说话的时候有背景的音乐、或者是会议室里面有多个人同时说话——这些情况下现在的语音识别效果是很差的。所以我们也在研究如何用深度学习的方法在比如多说话人的情况下做得比原来传统的方法好。我们现在已经在 arXiv 上面发布了一个早期结果的预印本(Permutation Invariant Training of Deep Models for Speaker-Independent Multi-talker Speech Separation),含有更多实验结果的正式版本现在正在审稿中。我们的这一称为 Permutation Invariant Training 的方法主要用于语音分离。用这种方法整个 process 比较简单而效果很好。在这些方面深度学习都能带来一定的突破。当然,我前面也讲了,完全解决这些问题需要软硬结合,从拾音到前端和后端需要系统性优化。
机器之心:在类似汉语这种多音字、多音词比较多的语言中,语音识别方面有什么和英语这样的拼音语言不一样的地方?
俞栋:从语音识别的技术角度来讲,没有太大的区别。因为你最终都是将语音信号,即 waveform sequence,变成字或者词的 sequence。多音字和多音词只是词表里对应的字或词有多个发音规则而已,这在其他语言比如英语中也很常见。
不过中文是一个有音调的语言,音调对字和词的识别是有影响的。音调信息如果用好的话,就有可能提升识别率。不过大家发现 deep learning 模型有很强的非线性映射功能,很多音调里的信息可以被模型自动学到,不需要特别处理。
唯一可能不一样的地方是如果你用 end-to-end system,建模单元会不一样。因为在英语里面你一般会选用字母、音素、或音节 作为建模单元,而不会选用词作为建模单元。但在中文里面你可以直接用汉字作为建模单元。所以建模单元的选择上可能会不太一样。除此之外,基本上没有太大区别。
机器之心:技术上没有太大区别?
俞栋:没有太大区别。
机器之心:具体来说,您觉得自然语言处理能够给语音识别带来哪些帮助?
俞栋:目前来讲,自然语言处理对语音识别本身的帮助还不是很大。要说帮助比较大的方面——如果语言模型(language model)算做自然语言处理的话,语言模型还是起到了很大作用的,尤其是在有噪音的环境下,如果没有语言模型来做约束,效果一般来说都比较差。但是除此之外,现在的 NLP 技术对语音识别没有起到很大的作用。大家尝试过很多用自然语言处理技术提升识别率的方法,但效果都不理想。
但是理论上来讲它应该是可以起到作用的。因为我们理解句子含义,我们能发现有一些语音识别结果是不 make sense 的,比如说前面的主语跟后面的宾语根本就不搭,在这种情况下识别系统应该选择其他的 hypothesis,对话系统则应该寻求澄清,但是现有系统没有这么做。没有这么做的原因在于它其实不理解到底用户说了什么,也没能充分利用远距离的 dependency 信息。这样的错误,有可能通过自然语言处理的技术发现并得到更正。但是语义分析是个很困难的问题,如何做还是一个未知数。
机器之心:刚才我们讲到在噪音环境下,包括远距离环境下的识别,除了这个,还有多个说话人一起说话的情况下的语音识别。在这三个方面,您觉得现在和未来可以通过什么样的方式来解决这个问题?
俞栋:前面提到过,解决远距离识别很重要的一点是需要硬件的支持。至少以目前的技术,仅仅通过后端处理效果还不够好。因为信号在传输的过程中衰减很厉害,距离越远衰减越厉害,信噪比就越差。所以远距离识别一般都需要做增强。比较好的增强需要硬件支持,比如说麦克风阵列。深度学习方法也能提供一些帮助。当你有多通道信息的时候,深度学习方法还可以做自动的信息融合以提升远距离语音识别的性能。
多通道信号处理,比如麦克风阵列,对分离含噪语音和多人混合语音也至关重要。另外,深度学习方法比如我刚才提到的 Permutation Invariant 训练方法也可以解决一部分语音分离问题,是整体解决方案中的重要一环。分离后的结果可以送到后端做识别。后端的识别结果反馈回来也能帮助提升分离和说话人跟踪的效果。所以最终的系统应该是前端的分离跟后端的识别融合互助的系统。
")
机器之心:从您和邓力老师的那本书《Automatic Speech Recognition: A Deep Learning Approach》出版到现在,您认为期间深度学习有了什么新的研究成果? 哪些研究成果您认为是很重大的?
俞栋:我们写这本书的时候,LSTM 这样的模型才刚刚开始成功应用于语音识别。当时大家对其中的很多 技巧 还没有很好的了解。所以训练出来的模型效果还不是那么好。最近,我的同事 Jasha Droppo 博士花了很多时间在 LSTM 模型上面,提出了一种很有意思的基于 smoothing 的 regularization 方法使得 LSTM 模型的性能有了很大的提升。他的 smoothing 方法的基本思想在我们的 human parity 文章中有介绍。
另外一个比较大的进展是 Deep CNN。最近两年里,很多研究组都发现或证实使用小 Kernel 的 Deep CNN 比我们之前在书里面提到的使用大 kernel 的 CNN 方法效果更好。Deep CNN 跟 LSTM 比有一个好处。用 LSTM 的话,一般你需要用双向的 LSTM 效果才比较好。但是双向 LSTM 会引入很长的时延,因为必须要在整个句子说完之后,识别才能开始。而 Deep CNN 的时延相对短很多,所以在实时系统里面我们会更倾向于用 Deep CNN 而不是双向 LSTM。
还有就是端到端的训练方式也是在我们的书完成后才取得进展的。这方面现在大家的研究工作主要集中在两类模型上。一类就是 CTC 模型,包括 Johns Hopkins 大学的 Dan Povey 博士从 CTC 发展出来的 lattice-free MMI;还有一类是 attention-based sequence to sequence model。这些模型在我们的书里面都没有描述,因为当时还没有做成功。即便今天它们的表现也还是比 hybrid model 逊色,训练的稳定性也更差,但是这些模型有比较大的 potential。如果继续研究有可能取得突破。
另外一个进展是单通道语音分离,尤其是多人混合语音的分离。这方面有两项有趣的工作。一个是 MERL 的 John Hershey 博士提出的 Deep Clustering 方法,另外一个是我们提出的 Permutation Invariant Training。实现上,Permutation Invariant Training 更简单。John Hershey 认为有迹象表明 deep clustering 是 permutation invariant training 的一个特例。
这些都是在我们完书之后最近两年里比较有意义的进展。
机器之心:也是在这个月,Google 发了神经网络翻译系统(GNMT),您对这个系统有什么看法?微软在这方面有没有这样的研究?
俞栋:微软很早以前就在做类似的工作了。你可能知道微软有个基于文本的翻译系统,在 Skype 上也有一个 speech to speech translation system。在这些系统里我们已经用到了 neural machine translation 的一些东西。不过翻译主要是由另外的团队在做,我在这里面涉及比较少。
机器之心:语音特征参数提取与鲁棒性语音识别与合成的关键因素,特征参数在不利的噪声环境下,鲁棒性都会急剧下降。目前有什么新的研究可以在特征提取中保持语音信号的最重要参数吗?
俞栋:目前,一个方法是用信号处理技术对输入信号进行分离和增强。另一个方法是用 deep learning 取代人工从 waveform 直接提取特征。只要训练数据的 coverage 足够大,各种各样场景的训练数据都有,模型的结构设计合理,那么模型的泛化能力和鲁棒性就能得到提升。两种方式结合可以得到更好结果。不过,泛化是机器学习的一个未解决的基本问题,更好的解决方案有待于机器学习理论的进展。
机器之心:微软在语音识别上如何解决方言带来的口音问题,比如说「le」和「ne」?针对方言,微软的语料库是从何而来的?
俞栋:一个简单的方法是增加带口音的训练语料。如何有效利用这些语料有些讲究。大概 3、4 年前,我们发过一篇文章,研究怎么样在 deep learning model 上做自适应。带口音的识别问题可以看作一个自适应的问题。假设你已经有标准语音的模型,带口音的语音可以看成标准语音的某种偏离。所以我们的解决方法是做自适应。做自适应的时候,我们可以把有类似口音的语料聚合在一起以增加训练数据。我们发现这样做效果挺不错。如果已经有系统上线,收集带口音的语料并不困难。如果你用过 Windows Phone,你就知道 Windows Phone 的 Cortana 里面有个选项——你想用标准的识别模型还是想用含口音的模型?用户可以选择。
机器之心:今年,微软发布了 CNTK。您能说一下 CNTK 跟 Theano、TensorFlow、Torch、Caffe 这些工具的区别吗?以及在微软语音系统上是怎么样应用 CNTK 的?
俞栋:所有的这些开源工具现在都做得相当好了,都能够满足一般的研究或者是工程的需要。但是每一个开源工具都有自己的长处和弱点。CNTK 是唯一一个对 Windows 和 Linux 都有比较好的支持的深度学习工具。相比较其他工具,CNTK 对多 GPU 并行训练有更好的支持, 不仅并行效率高,而且简单易用。CNTK 对 C++的支持也是最全面的,你可以完全使用 C++来构建、训练、修改、和解码模型。CNTK 版本 1 对 Python binding 支持比较弱。但是刚刚发布的版本 2.0 提供了非常强大的 Python binding。另外,CNTK 提供了许多运行效率很高的并行文件阅读模块,大大提升了并行效率。这里我想提一下,我的很多同事都对 CNTK 2.0 有很大贡献。尤其值得一提的是 Amit Agarwal,他是我见过的非常难得的优秀软件工程师和架构师,他主导设计了 CNTK2.0 的主要 API。我在他身上学到很多东西,我非常享受与他讨论的时间。
我和几个同事刚开始写 CNTK1.0 的时候,主要用户是语音识别研究员和工程师,所以 CNTK 对语音相关的模型、数据结构、和文件格式支持得相对比较好。因为语音识别系统训练数据很大,我们很早就在 CNTK 中实现了并行训练的算法。目前,微软产品线所有的语音识别模型都是用 CNTK 训练的。最近我们的语音识别系统在 SWB 数据集上能做到比专业转录员错误率还低,CNTK 对缩短我们达到这一里程碑所需的时间有很大贡献。
机器之心:您曾说过,人工智能的成功在于将多种方法的整合到一个系统。在你们最近发表的论文中,我们看到目前最新的语音识别的研究用到了多任务优化(Multitask Joint learning)以及多种模型混合(ensembles of models)的方法,能谈谈他们的优势吗?
俞栋:语音识别相对来说是一个任务比较单一而非通用的人工智能系统。语音识别的问题定义得也比较清晰。在这样的系统里面,把深度学习模型与其他模型进行整合的重要性相对来说比较小。这也就是为什么只要你有足够的数据和运算能力,即便是完全的 deep learning end-to-end system 表现也不错。不过目前来讲,深度学习和 HMM 相结合的混合模型在大多数场景下仍然表现最佳。
语音识别中使用多任务优化的主要目的是增加模型的泛化能力或利用一些不能直接利用的辅助信息。而多种模型混合(ensembles of models)的主要目的是利用模型间的差异来增强混合后模型的表现。值得指出的是,由于深度学习模型是非线性非凸的优化问题,当初始模型不同时,最后的模型也不同。尽管这些模型的平均表现很接近,但因为他们收敛到的点不一样,模型之间仍有差异,融合这些模型也能提升一些性能。
但是更通用的人工智能系统还需要能做决策(decision-making)、要做推理、要能理解。对于这样的系统来说,单靠深度学习方法远远不够。而需要结合过去几十年里人工智能其他分支取得的一些进展,比如说增强学习、逻辑推理、知识表达、以及最优和次优搜索。还有如果我们想让一群人工智能系统自己从与环境的交互中快速寻找答案,那么诸如蚁群算法和遗传算法一类的算法就变得很重要了。
机器之心:今年您觉得在语音识别方面有哪些比较重量级的论文值得去读,能否推荐几个给我们的读者?
俞栋:除了前面提到的 LF-MMI 、 Deep CNN(包括我们最近发表的 LACE 模型)、和 Permutation Invariant Training,另外一个比较有意思的论文是 MERL 在 arXiv 上发表的一篇文章。他们结合了 CTC 和 attention-based model,利用这两个模型各自的长处来克服对方的弱点。
机器之心:您是怎么看待监督学习、半监督学习和无监督学习这三个学习方式呢?
俞栋:监督学习是比较 well-defined,有比较明确的任务。目前来讲,深度学习对这一类问题 效果比较好。
无监督学习的目的是要寻找数据中的潜在规律。很多情况下,它试图寻找某种特征变换和相对应的生成模型来表达原始数据。但无监督学习不仅本身困难,对无监督学习系统的评价也很难。原因是通过无监督学习找到的规律不一定对你将来的任务有帮助,或者它对某一任务有帮助,换一个 任务就没有帮助了。当然,如果你的目标仅仅是数据压缩,评价还是容易的,但我们使用无监督学习压缩本身往往不是主要目的。
机器之心:那半监督学习呢?
俞栋:半监督学习介于两者中间。因为你已经有一部分标注信息了,所以你 的任务是明确的,不存在不知如何评估的问题。半监督学习在实用系统里还是有一定作用的。比如说我们需要标注大量数据来训练语音识别系统,但人工标注既花时间又花钱,所以你往往有比标注数据多得多的未标注数据。没有标注过的数据,也有很多可以利用的信息,虽然它们的价值远远小于标注的数据。半监督学习对我们的系统性能有一定的提升。
机器之心:最后一个问题,在整个人工智能的布局上,您认为语音识别是一个怎样的定位?
俞栋:在很多应用场合,语音识别是一个入口。没有这个入口的话,大家都会觉得这个智能机器不够智能或者与这个智能机器交互会有困难。人机交互中语音识别是第一步。如果语音识别做得不够好,那后期的自然语言理解等的错误率就会大幅上升。这也是为什么语音到语音的翻译要比文本到文本的翻译难很多,因为在语音对语音的翻译系统里语音识别产生的错误会在后面翻译的过程中放大。
历史上,语音识别也为机器学习和人工智能提供了很多新的方法和解决方案。比如语音识别里的关键模型 Hidden Markov Model 对后来机器学习的很多分支都有帮助。深度学习也是先在语音识别上取得成功,然后才在图像识别和其他领域取得成功的。
专访 | 微软人物志
微软研究院人工智能首席科学家 | 邓力
微软首席语音科学家 | 黄学东
微软亚洲研究院院长 | 洪小文
微软(亚洲)互联网工程院院长 | 王永东
微软亚洲研究院首席研究员 | 霍强
机器之心
相关推荐
- AI技术免费拍证件照:未来的便捷之选,ai证件照app
-
随着人工智能技术的飞速发展,我们的生活变得越来越便捷。其中,利用AI免费拍摄证件照的服务,就是这一技术进步的直接体现。这项服务不仅节省了人们前往照相馆的时间和金钱,还提供了一种高效、便捷的拍照方式。接...
- AI生活节:未来科技如何改变我们的日常,ai生活节买票图片大全
-
在这个信息爆炸的时代,人工智能(AI)已经不再是科幻小说中的概念,而是逐渐渗透到我们生活的方方面面。从智能家居到自动驾驶,从在线客服到个性化推荐,AI技术正在以前所未有的速度改变着我们的生活方式。而“...
- AI定制祝福语:让你的朋友圈与众不同,自定义祝福语
-
在这个科技飞速发展的时代,人工智能(AI)已经渗透到我们生活的方方面面。从智能家居到在线客服,再到个性化推荐系统,AI技术正在改变我们的生活方式。然而,你有没有想过,AI也能帮你定制出惊艳的朋友圈祝福...
- AI画头像:未来肖像艺术的新纪元,
-
在这个快速发展的数字时代,人工智能(AI)已经渗透到我们生活的方方面面,从家庭助理到自动驾驶汽车,AI技术正在不断突破我们的想象。其中,AI画头像作为一种新兴的科技应用,不仅让我们对艺术创作有了新的认...
- AI会议系统:未来工作沟通的新篇章,ai会议助手
-
在数字化时代,会议系统作为企业沟通和协作的重要工具,一直在不断地演变和进步。近年来,随着人工智能技术的飞速发展,AI会议系统应运而生,它不仅改变了我们召开和参与会议的方式,还极大地提升了会议效率和质量...
- 星际争霸2中的AI:从对手到合作伙伴,星际争霸1重制版
-
在电子竞技的宇宙中,星际争霸2一直是一个标志性的存在。这款由暴雪娱乐开发的即时战略游戏因其复杂的游戏机制和深度策略而闻名。近年来,随着人工智能(AI)技术的发展,星际争霸2中的AI已经从一个简单的电脑...
- 真三国无双AI:游戏中的历史与智能碰撞,真三国无双 ai cn
-
在电子游戏的世界中,历史题材与人工智能(AI)的结合日益紧密,尤其是在策略和动作类游戏领域。《真三国无双》系列游戏,作为一款以中国三国时期为背景的动作游戏,近年来在AI技术上的融合,为玩家带来了全新的...
- 探索909ai.com:未来科技的门户,
-
在我们快速发展的科技时代,每一个创新都可能成为引领未来的关键。今天,我们将深入探讨一个神秘而又充满潜力的网站——909ai.com。它不仅仅是一个网址,更是连接我们与未来科技的一座桥梁。让我们一起揭开...
- 探索DOTA6.77AI版本下载的奥秘,dota6.88ai下载
-
在电子竞技的宇宙中,DOTA(DefenseoftheAncients)一直是一颗璀璨的星。自从2003年首次亮相以来,它已经吸引了全球数百万的玩家,并且随着时间的推移,它不断地演化和升级。今天...
- 探索Dota6.78AI地图的全新体验,
-
Dota2作为一款风靡全球的多人在线战斗竞技游戏,其AI版本的推出,为广大玩家带来了无限乐趣。在众多版本中,Dota6.78AI地图凭借其独特的玩法和改进的AI系统,吸引了众多玩家的目光。本文将...
- 魔兽真三AI地图:人工智能在游戏中的新纪元,魔兽真三ai地图电脑版
-
随着人工智能技术的迅猛发展,AI已经渗透到我们生活的方方面面。在游戏领域,AI的应用也日益广泛,尤其是魔兽争霸III的自定义地图“真三”中的AI,它不仅提升了游戏体验,还为玩家带来了全新的挑战和乐趣。...
- 由于我是一个大型语言模型,我无法访问外部网站或验证特定网站的存在。因此,我将创造一个虚构的网站,[www.550ai.com],并围绕这个主题撰写一篇文章。,
-
由于我是一个大型语言模型,我无法访问外部网站或验证特定网站的存在。因此,我将创造一个虚构的网站,[www.550ai.com],并围绕这个主题撰写一篇文章。在数字时代,人工智能(AI)已经成为推...
- 会员中心
-
- 百度热搜
- 新浪热搜
- 最新抖音
- 最新快手
-

抖音在线挖玉:短视频里的宝石探秘之旅,抖音挖矿赚钱app下载
在数字时代的浪潮下,短视频平台如抖音已经成为人们获取信息、娱乐消遣的重要渠道。近年来,抖音上兴起了一...

抖音短视频:现代人的快乐源泉,我想看抖音里的搞笑片
在这个快节奏的时代,人们越来越需要快速、轻松的娱乐方式来缓解压力。抖音短视频平台以其搞笑内容的丰富性...

探索抖音在线观看的无限世界,抖音在线网址打开
在这个数字时代,短视频平台已经成为人们日常生活中不可或缺的一部分。抖音,作为其中的佼佼者,凭借其丰富...
快手下载的视频怎么去掉快手号,快手下载视频怎么去掉快手号水印
现在我要给大家介绍这样一款游戏快手下载的视频怎么去掉快手号,这款游戏自从推出就登上了各大平台快手...

快手小游戏破解版游戏大全(快手小游戏破解挂)
快手小游戏破解版游戏大全我的世界中国版红石发射器合成攻略中国版红石发射器怎么合成?红石发射器是...

快手下载最新版本2023红包版,快手下载最新版本2023
第二步快手下载最新版本2023,打开豌豆荚搜索界面搜索“快手”快手下载最新版本2023,然后在搜索结...

快手下载别人作品对方知道吗,快手下载别人作品会不会有提醒
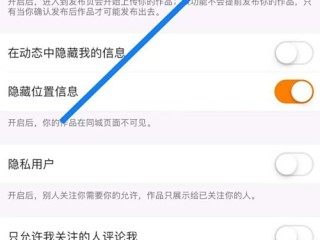
1、1快手下载人家作品知道快手下载别人作品对方知道吗,因为会有下载记录,只要访问别人的主页查看作品的...
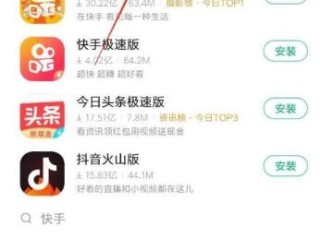
下载快手app(下载快手app下载)
打开手机的浏览器下载快手app,进入快手的官方首页在官方首页上,通常会有下载快手APP的链接或按钮点...
- 热门关注
 滇公网安备53310202533258
滇公网安备53310202533258